
Plan for this week
Last week:
- built-in data types
- base types, tuples, lists (and strings)
- writing functions using pattern matching and recursion
This week:
- user-defined data types
- and how to manipulate them using pattern matching and recursion
- more details about recursion
Representing complex data
We’ve seen:
- base types:
Bool,Int,Integer,Float some ways to build up types: given types
T1, T2- functions:
T1 -> T2 - tuples:
(T1, T2) - lists:
[T1]
- functions:
Algebraic Data Types: a single, powerful technique for building up types to represent complex data
- Lets you define your own data types
- Tuples and lists are special cases
Building data types
Three key ways to build complex types/values:
Product types (each-of): a value of
Tcontains a value ofT1and a value ofT2Sum types (one-of): a value of
Tcontains a value ofT1or a value ofT2Recursive types: a value of
Tcontains a sub-value of the same typeT
Product types
Tuples can do the job but there are two problems…
deadlineDate :: (Int, Int, Int)
deadlineDate = (2, 4, 2019)
deadlineTime :: (Int, Int, Int)
deadlineTime = (11, 59, 59)
-- | Deadline date extended by one day
extension :: (Int, Int, Int) -> (Int, Int, Int)
extension = ...Can you spot them?
1. Verbose and unreadable
A type synonym for T: a name that can be used interchangeably with T
type Date = (Int, Int, Int)
type Time = (Int, Int, Int)
deadlineDate :: Date
deadlineDate = (2, 4, 2019)
deadlineTime :: Time
deadlineTime = (11, 59, 59)
-- | Deadline date extended by one day
extension :: Date -> Date
extension = ...
2. Unsafe
We want this to fail at compile time!!!
Solution: construct two different datatypes
data Date = Date Int Int Int
data Time = Time Int Int Int
-- constructor^ ^parameter types
deadlineDate :: Date
deadlineDate = Date 2 4 2019
deadlineTime :: Time
deadlineTime = Time 11 59 59
Record syntax
Haskell’s record syntax allows you to name the constructor parameters:
Instead of
you can write:
then you can do:
Building data types
Three key ways to build complex types/values:
Product types (each-of): a value of
Tcontains a value ofT1and a value ofT2[done]Sum types (one-of): a value of
Tcontains a value ofT1or a value ofT2Recursive types: a value of
Tcontains a sub-value of the same typeT
Example: NanoMarkdown
Suppose I want to represent a text document with simple markup
Each paragraph is either:
- plain text (
String) - heading: level and text (
IntandString) - list: ordered? and items (
Booland[String])
I want to store all paragraphs in a list
doc = [ (1, "Notes from 130") -- Level 1 heading
, "There are two types of languages:" -- Plain text
, (True, [ "those people complain about" -- Ordered list
, "those no one uses"])
]But this does not type check!!!
Sum Types
Solution: construct a new type for paragraphs that is a sum (one-of) the three options!
Each paragraph is either:
- plain text (
String) - heading: level and text (
Int&String) - list: ordered? and items (
Bool&[String])
data Paragraph -- ^ 3 constructors, w/ different parameters
= PText String -- ^ text: plain string
| PHeading Int String -- ^ head: level and text (Int & String)
| PList Bool [String] -- ^ list: ordered? & items (Bool & [String])
QUIZ
What is the type of Text "Hey there!"? i.e. How would GHCi reply to:
A. Syntax error
B. Type error
C. PText
D. String
E. Paragraph
Constructing datatypes
Tis the new datatypeC1 .. Cnare the constructors ofT
A value of type T is
- either
C1 v1 .. vkwithvi :: T1i - or
C2 v1 .. vlwithvi :: T2i - or …
- or
Cn v1 .. vmwithvi :: Tni
You can think of a T value as a box:
- either a box labeled
C1with values of typesT11 .. T1kinside - or a box labeled
C2with values of typesT21 .. T2linside - or …
- or a box labeled
Cnwith values of typesTn1 .. Tnminside

Constructing datatypes: Paragraph
Apply a constructor = pack some values into a box (and label it)
PText "Hey there!"- put
"Hey there!"in a box labeledPText
- put
PHeading 1 "Introduction"- put
1and"Introduction"in a box labeledPHeading
- put
- Boxes have different labels but same type (
Paragraph)

Paragraph Typewith example values:

Paragraph Type
QUIZ
What would GHCi say to
A. Syntax error
B. Type error
C. Paragraph
D. [Paragraph]
E. [String]
Example: NanoMD
Now I can create a document like so:
doc :: [Paragraph]
doc = [ PHeading 1 "Notes from 130"
, PText "There are two types of languages:"
, PList True [ "those people complain about"
, "those no one uses"
])
]
Now I want convert documents in to HTML.
I need to write a function:
How to tell what’s in the box?
- Look at the label!
Pattern matching
Pattern matching = looking at the label and extracting values from the box
- we’ve seen it before
- but now for arbitrary datatypes
html :: Paragraph -> String
html (PText str) = ... -- It's a plain text! Get string
html (PHeading lvl str) = ... -- It's a heading! Get level and string
html (PList ord items) = ... -- It's a list! Get ordered and items
html :: Paragraph -> String
html (PText str) -- It's a plain text! Get string
= unlines [open "p", str, close "p"]
html (PHeading lvl str) -- It's a heading! Get level and string
= let htag = "h" ++ show lvl
in unwords [open htag, str, close htag]
html (PList ord items) -- It's a list! Get ordered and items
= let ltag = if ord then "ol" else "ul"
litems = [unwords [open "li", i, close "li"] | i <- items]
in unlines ([open ltag] ++ litems ++ [close ltag])
Dangers of pattern matching (1)
What would GHCi say to:
Dangers of pattern matching (2)
html :: Paragraph -> String
html (PText str) = unlines [open "p", str, close "p"]
html (PHeading lvl str) = ...
html (PHeading 0 str) = html (PHeading 1 str)
html (PList ord items) = ...What would GHCi say to:
Dangers of pattern matching
Beware of missing and overlapped patterns
- GHC warns you about overlapped patterns
- GHC warns you about missing patterns when called with
-W(use:set -Win GHCi)
Pattern-Match Expression
Everything is an expression?
We’ve seen: pattern matching in equations
Actually, pattern-match is also an expression
html :: Paragraph -> String
html p = case p of
PText str -> unlines [open "p", str, close "p"]
PHeading lvl str -> ...
PList ord items -> ...The code we saw earlier was syntactic sugar
is just for humans, internally represented as a case-of expression
QUIZ
What is the type of
A. Syntax error
B. Type error
C. String
D. Paragraph
E. Paragraph -> String
Pattern matching expression: typing
The case expression
has type T if
- each
e1…eNhas typeT ehas some typeD- each
pattern1…patternNis a valid pattern forD- i.e. a variable or a constructor of
Dapplied to other patterns
- i.e. a variable or a constructor of
The expression e is called the match scrutinee
QUIZ
What is the type of
A. Syntax error
B. Type error
C. Paragraph
D. Int
E. Paragraph -> Int
Building data types
Three key ways to build complex types/values:
Product types (each-of): a value of
Tcontains a value ofT1and a value ofT2[done]- Cartesian product of two sets: v(T) = v(T1) × v(T2)
Sum types (one-of): a value of
Tcontains a value ofT1or a value ofT2[done]- Union (sum) of two sets: v(T) = v(T1) ∪ v(T2)
Recursive types: a value of
Tcontains a sub-value of the same typeT
Recursive types
Let’s define natural numbers from scratch:
A Nat value is:
- either an empty box labeled
Zero - or a box labeled
Succwith anotherNatin it!
Some Nat values:
Functions on recursive types
Recursive code mirrors recursive data
1. Recursive type as a parameter
Step 1: add a pattern per constructor
toInt :: Nat -> Int
toInt Zero = ... -- base case
toInt (Succ n) = ... -- inductive case
-- (recursive call goes here)Step 2: fill in base case:
toInt :: Nat -> Int
toInt Zero = 0 -- base case
toInt (Succ n) = ... -- inductive case
-- (recursive call goes here)Step 2: fill in inductive case using a recursive call:
QUIZ
What does this evaluate to?
A. Syntax error
B. Type error
C. 2
D. Succ Zero
E. Succ (Succ Zero)
2. Recursive type as a result
data Nat = Zero -- base constructor
| Succ Nat -- inductive constructor
fromInt :: Int -> Nat
fromInt n
| n <= 0 = Zero -- base case
| otherwise = Succ (fromInt (n - 1)) -- inductive case
-- (recursive call goes here)
3. Putting the two together
data Nat = Zero -- base constructor
| Succ Nat -- inductive constructor
add :: Nat -> Nat -> Nat
add n m = ???
sub :: Nat -> Nat -> Nat
sub n m = ???
data Nat = Zero -- base constructor
| Succ Nat -- inductive constructor
add :: Nat -> Nat -> Nat
add Zero m = m -- base case
add (Succ n) m = Succ (add n m) -- inductive case
sub :: Nat -> Nat -> Nat
sub n Zero = n -- base case 1
sub Zero _ = Zero -- base case 2
sub (Succ n) (Succ m) = sub n m -- inductive caseLessons learned:
- Recursive code mirrors recursive data
- With multiple arguments of a recursive type, which one should I recurse on?
- The name of the game is to pick the right inductive strategy!
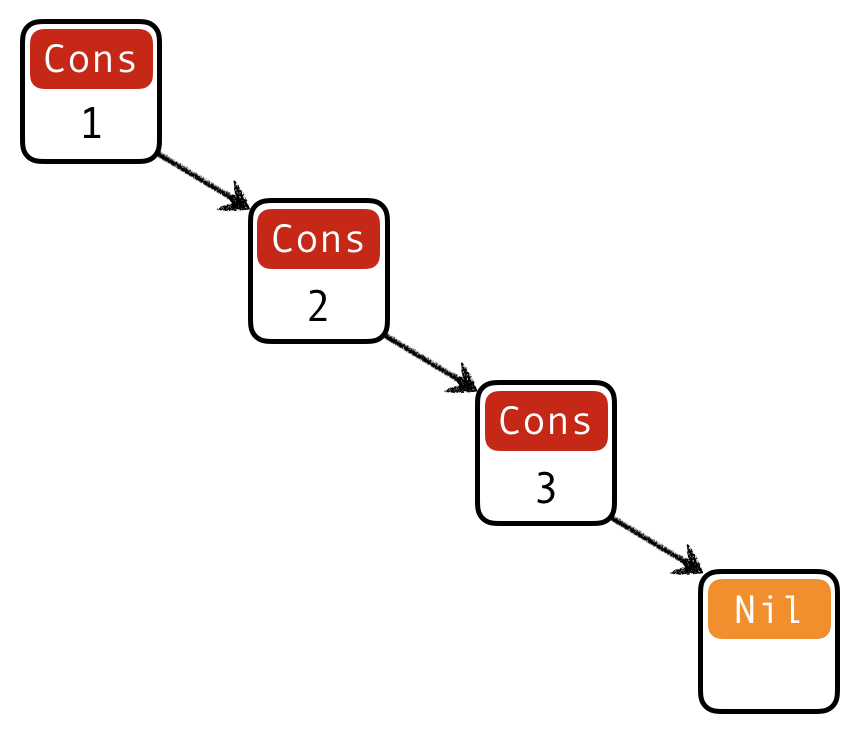
Lists
Lists aren’t built-in! They are an algebraic data type like any other:
List
[1, 2, 3]is represented asCons 1 (Cons 2 (Cons 3 Nil))Built-in list constructors
[]and(:)are just fancy syntax forNilandCons
Functions on lists follow the same general strategy:
length :: List -> Int
length Nil = 0 -- base case
length (Cons _ xs) = 1 + length xs -- inductive case
What is the right inductive strategy for appending two lists?
Trees
Lists are unary trees with elements stored in the nodes:
How do we represent binary trees with elements stored in the nodes?
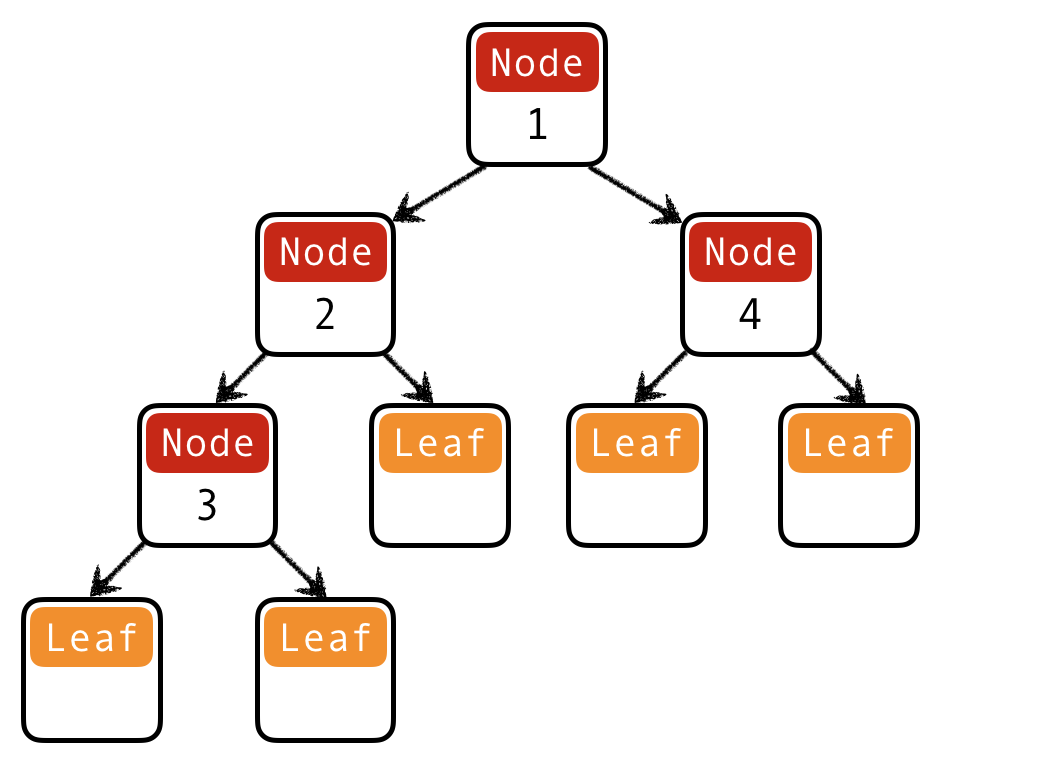
QUIZ: Binary trees I
What is a Haskell datatype for binary trees with elements stored in the nodes?
(A) data Tree = Leaf | Node Int Tree
(B) data Tree = Leaf | Node Tree Tree
(C) data Tree = Leaf | Node Int Tree Tree
(D) data Tree = Leaf Int | Node Tree Tree
(E) data Tree = Leaf Int | Node Int Tree Tree
data Tree = Leaf | Node Int Tree Tree
t1234 = Node 1
(Node 2 (Node 3 Leaf Leaf) Leaf)
(Node 4 Leaf Leaf)
Functions on trees
QUIZ: Binary trees II
What is a Haskell datatype for binary trees with elements stored in the leaves?
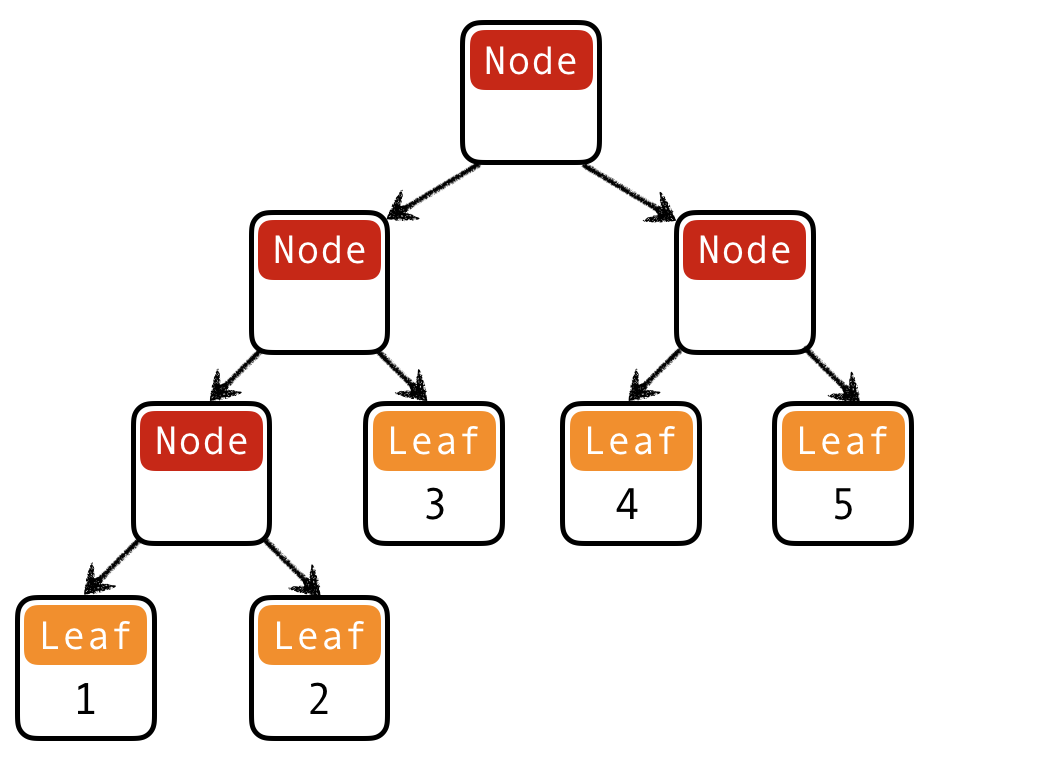
(A) data Tree = Leaf | Node Int Tree
(B) data Tree = Leaf | Node Tree Tree
(C) data Tree = Leaf | Node Int Tree Tree
(D) data Tree = Leaf Int | Node Tree Tree
(E) data Tree = Leaf Int | Node Int Tree Tree
data Tree = Leaf Int | Node Tree Tree
t12345 = Node
(Node (Node (Leaf 1) (Leaf 2)) (Leaf 3))
(Node (Leaf 4) (Leaf 5))
Example: Calculator
I want to implement an arithmetic calculator to evaluate expressions like:
4.0 + 2.93.78 – 5.92(4.0 + 2.9) * (3.78 - 5.92)
What is a Haskell datatype to represent these expressions?
How do we write a function to evaluate an expression?
Recursion is…
Building solutions for big problems from solutions for sub-problems
- Base case: what is the simplest version of this problem and how do I solve it?
- Inductive strategy: how do I break down this problem into sub-problems?
- Inductive case: how do I solve the problem given the solutions for subproblems?
Why use Recursion?
Often far simpler and cleaner than loops
- But not always…
Structure often forced by recursive data
Forces you to factor code into reusable units (recursive functions)
Why not use Recursion?
Slow
Can cause stack overflow
Example: factorial
Lets see how fac 4 is evaluated:
<fac 4>
==> <4 * <fac 3>> -- recursively call `fact 3`
==> <4 * <3 * <fac 2>>> -- recursively call `fact 2`
==> <4 * <3 * <2 * <fac 1>>>> -- recursively call `fact 1`
==> <4 * <3 * <2 * 1>>> -- multiply 2 to result
==> <4 * <3 * 2>> -- multiply 3 to result
==> <4 * 6> -- multiply 4 to result
==> 24
Each function call <> allocates a frame on the call stack
- expensive
- the stack has a finite size
Can we do recursion without allocating stack frames?
Tail Recursion
Recursive call is the top-most sub-expression in the function body
i.e. no computations allowed on recursively returned value
i.e. value returned by the recursive call == value returned by function
QUIZ: Is this function tail recursive?
A. Yes
B. No
Tail recursive factorial
Let’s write a tail-recursive factorial!
Lets see how facTR is evaluated:
<facTR 4>
==> <<loop 1 4>> -- call loop 1 4
==> <<<loop 4 3>>> -- rec call loop 4 3
==> <<<<loop 12 2>>>> -- rec call loop 12 2
==> <<<<<loop 24 1>>>>> -- rec call loop 24 1
==> 24 -- return result 24! Each recursive call directly returns the result
without further computation
no need to remember what to do next!
no need to store the “empty” stack frames!
Why care about Tail Recursion?
Because the compiler can transform it into a fast loop
function facTR(n){
var acc = 1;
while (true) {
if (n <= 1) { return acc ; }
else { acc = acc * n; n = n - 1; }
}
}Tail recursive calls can be optimized as a loop
- no stack frames needed!
Part of the language specification of most functional languages
- compiler guarantees to optimize tail calls
That’s all folks!